


논문 리뷰
1. 사용한 Data
- ImageNet dataset
22,000개 범주로 구성되어 있고 1500만개의 고해상도 이미지가 포함되어있는 data set
- 이미지 크기 256x256으로 고정
resize 방법은 이미지의 넓이와 높이 중 더 짧은 쪽을 256으로 고정시키고 중앙 부분을 256x256 크기로 crop
(이후 augmentation을 위해 227X227로 자르긴 한다.)
2. 구조

Input layer - Conv1 - MaxPool1 - Norm1 - Conv2 - MaxPool2 - Norm2 - Conv3 - Conv4 - Conv5 - MaxPool3 - FC1 - FC2 - Output layer순서
3. 활성화 함수
ReLU
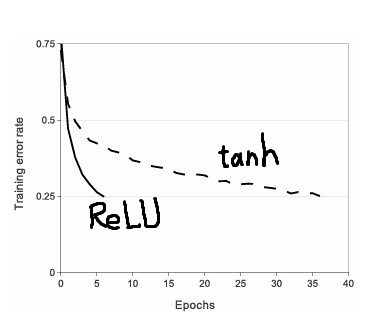
4. 2개의 GPU로 나누어 학습
구현시에는 2개로 나누어서 학습하지않고 1개로 할 예정(GPU가 1개라서)
5. Local Response Normalization (LRN)
추후에는 LRN은 사용하지 않고 Batch Normalization만 사용하게 되었다.
Why?
=> (확인 후 추후 업데이트)
논문 구현
데이터는 Cifar10을 사용했다. (10종류로 분류된 데이터) + Google Colab 환경에서 작업했다. (하다가 GPU 사용량 초과됐다고 막아버림.. Pro 결제해야하나..)
1. 먼저 필요한 라이브러리를 import
import torch
import torch.nn as nn
import torch.nn.functional as F
from torchsummary import summary
from torchvision import transforms, datasets
import torch.optim as optim
import torchvision
import os
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
2. AlexNet 모델 구현
위의 그림에서 주어진 대로 하나하나 쌓아나가면 된다.
- FC를 기점으로 2개로 나누어서 nn.Sequential에 layer를 쌓았다. (중간에 flatten해야해서 + 가독성)
- Dropout 위치 nn.Linear(), nn.ReLU 전에 와야 하는지 다음에 와야하는지?
=> (확인 후 추후 업데이트)
class AlexNet(nn.Module):
def __init__(self):
super(AlexNet, self).__init__()
self.net = nn.Sequential(
nn.Conv2d(in_channels=3, out_channels=96, kernel_size=11, stride=4, padding=2),
nn.ReLU(inplace=True),
nn.LocalResponseNorm(size=5, alpha=0.0001, beta=0.75, k=2), # LRN
nn.MaxPool2d(kernel_size=3, stride=2),
nn.Conv2d(in_channels=96, out_channels=256, kernel_size=5, stride=1, padding=2),
nn.ReLU(inplace=True),
nn.LocalResponseNorm(size=5, alpha=0.0001, beta=0.75, k=2), # LRN
nn.MaxPool2d(kernel_size=3, stride=2),
nn.Conv2d(in_channels=256, out_channels=384, kernel_size=3, stride=1, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(in_channels=384, out_channels=384, kernel_size=3, stride=1, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(in_channels=384, out_channels=256, kernel_size=3, stride=1, padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2),
)
self.fc = nn.Sequential(
nn.Dropout(p=0.5),
nn.Linear(in_features=6*6*256, out_features=4096), # fc1
nn.ReLU(inplace=True),
nn.Dropout(p=0.5),
nn.Linear(in_features=4096, out_features=4096), # fc2
nn.ReLU(inplace=True),
nn.Linear(in_features=4096, out_features=10), # fc3
)
def forward(self, x):
x = self.net(x)
# x = x.view(-1, 256 * 6 * 6)
# x = x.view(x.size(0), -1) # 4차원을 1차원으로 펼쳐주는 층 (역할) -> flatten
x = torch.flatten(x, 1)
x = self.fc(x)
return self.classifier(x)
3. 하이퍼 파라미터 설정
batch_size = 512
num_epochs = 10
learning_rate = 0.0001
4. Data augmentation을 위해 torchvision.transforms + torchvision.transforms.Compose([]) 사용
- 처음에 transform한 데이터를 밑의 5번 코드에 있는 train_set을 확인해보았는데, 원본 데이터를 변환하는 것은 확인 했지만, 데이터를 늘려서 train하는지는 확인하지 못했다....
=> (확인 후 추후 업데이트)
transform = transforms.Compose([
transforms.ToTensor(),
# 추가
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
])
5. Cifar10 데이터를 다운로드하고, train, test set을 나누기 + nn.
root = './data'
train_set = datasets.CIFAR10( root=root, # 데이터 저장 위치
train=True, # True: train set, False: test set
download=True, # 다운로드 여부, (이미 다운받았으면 False로 지정)
transform=transform # 데이터 선처리 작업
)
train_loader = torch.utils.data.DataLoader(train_set, batch_size=batch_size, shuffle=True)
test_set = datasets.CIFAR10( root=root,
train=False,
download=True,
transform=transform
)
test_loader = torch.utils.data.DataLoader(test_set, batch_size=batch_size, shuffle=True)
6. GPU 사용가능한지 확인
device = ("cuda" if torch.cuda.is_available() else "cpu")
print(device)
7. Train, Test 코드 작성
# if gpu is to be used
use_cuda = torch.cuda.is_available()
print("use_cuda : ", use_cuda)
device = torch.device("cuda:0" if use_cuda else "cpu") # (CUDA를 사용할 수 있다면) 첫번째 CUDA 장치를 사용하도록 설정
model = AlexNet().to(device)
criterion = nn.CrossEntropyLoss().to(device) # 손실 함수
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate) # Adam, 논문에서는 adam말고 SGD쓴듯
def train(model, device, train_loader, optimizer, epoch):
model.train()
for batch_idx, (img, label) in enumerate(train_loader):
label = label.type(torch.LongTensor)
img, label = img.to(device), label.to(device)
optimizer.zero_grad() # 변화도(Gradient) 매개변수를 0으로 만듬
# 순전파 + 역전파 + 최적화
output = model(img)
loss = criterion(output, label)
# total_train_loss += loss.item() # 손실 그래프 그리기 위함
loss.backward()
optimizer.step()
if (batch_idx + 1) % 30 == 0:
print("Train Epoch:{} [{}/{} ({:.0f}%)]\tLoss: {:.6f}".format(
epoch, batch_idx * len(img), len(train_loader.dataset),
100. * batch_idx / len(train_loader), loss.item()))
def test(model, device, test_loader):
model.eval()
test_loss = 0
correct = 0
with torch.no_grad():
for img, label in test_loader:
img, label = img.to(device), label.to(device)
output = model(img)
test_loss += criterion(output, label, reduction='sum').item()
pred = output.max(1, keepdim=True)[1]
correct += pred.eq(label.view_as(pred)).sum().item()
test_loss /= len(test_loader.dataset)
print("\nTest set: Average loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)\n".format(
test_loss, correct, len(test_loader.dataset), 100. * correct / len(test_loader.dataset)))
print('='*50)
8. Train, Test 실행
for epoch in range(1, num_epochs + 1):
train(model, device, train_loader, optimizer, epoch)
test(model, device, test_loader)
결과는 다음과 같다.
=> (확인 후 추후 업데이트)